
学习记录-Pytorch CNN model
【有点乱,空了看心情再整理】
【想法】
- 没有模型,可以参数初始化

- 模型+模型 model
【资料卡】
【pycharm】
- 注释 ctrl+/ (如果突然用不了这个快捷键 抽风?一会儿好像又好了
- 全局搜索 Ctrl + Shift + F
【神经网络模型】
深度学习之PyTorch实战(2)——神经网络模型搭建和参数优化
!文章入门强烈推荐👍,写的非常详细。


- torch.nn.Linear类用于定义模型的线性层,即完成前面提到的不同的层之间的线性变换。
- torch.nn.ReLU类属于非线性激活分类。
- 【损失函数的具体用法】。。。
- 模型训练。引入了优化算法,所以通过直接调用optimzer.zero_grad来完成对模型参数梯度的归零;并且在以上代码中增加了optimzer.step,它的主要功能是使用计算得到的梯度值对各个节点的参数进行梯度更新。
- torch.optim:模型参数的优化
- torch.autograd:自动梯度

- model forward: 也就是说 ,当把定义的网络模型 model 当做函数调用的时候就自动调用定义的网络模型 forward方法。 可以看到,当执行 model(x) 的时候,底层自动调用 forward 方法计算结果。
- pytorch中 x = x.view(x.size(0), -1) 的理解: view() 函数的功能跟 reshape类似,用来转换size大小。x = x.view(batchsize, -1) 中的 batchsize 指转换后有几行,而 -1 指在不告诉函数有多少列的情况下,根据原tensor数据和batchsize自动分配列数。
- 全连接层 卷积层
全连接层
- 全连接层需要把输入拉成一个列项向量
- 卷积层就相当于一个卷积核,对于传送过来的feature map进行局部窗口滑动,无论你输入的feature map多大(不能小于卷积核的大小),都不会对卷积造成影响:

- 全连接层 时间复杂度_CNN各层与全连接层产生的参数计算方式
- 全连接层缺陷
全局平均池化层
https://zhuanlan.zhihu.com/p/46235425
- 在卷积神经网络的初期,卷积层通过池化层(一般是 最大池化)后总是要一个或n个全连接层,最后在softmax分类。其特征就是全连接层的参数超多,使模型本身变得非常臃肿。
- global average poolilng。既然全连接网络可以使feature map的维度减少,进而输入到softmax,但是又会造成过拟合,是不是可以用pooling来代替全连接。
答案是肯定的,Network in Network工作使用GAP来取代了最后的全连接层,直接实现了降维,更重要的是极大地减少了网络的参数(CNN网络中占比最大的参数其实后面的全连接层)。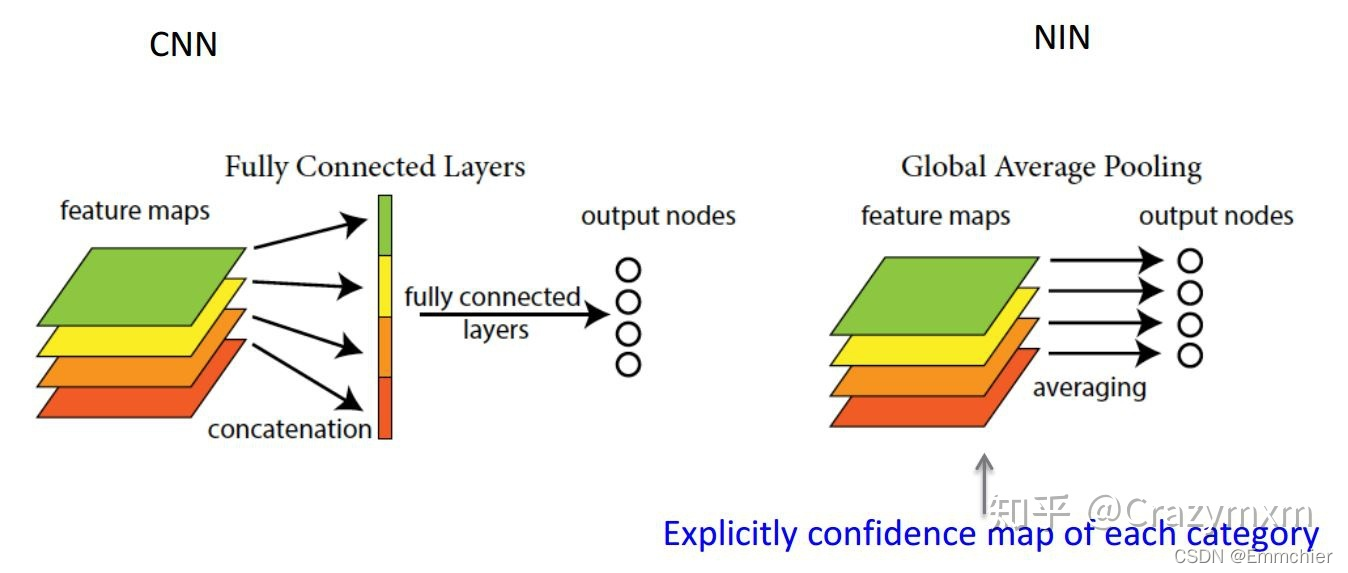
GAP的真正意义是:对整个网路在结构上做正则化防止过拟合。其直接剔除了全连接层中黑箱的特征,直接赋予了每个channel实际的内别意义。实践证明其效果还是比较可观的,同时GAP可以实现任意图像大小的输入。但是值得我们注意的是,使用gap可能会造成收敛速度减慢。 - 论文:Network In Network
- 关于使用GAP或者全局池化的好处,卷积神经网络在图像分类中,把卷积层作为特征提取,全链接层+softmax作为归回分类,这样方式会导致在全连接层输入神经元太多容易导致过拟合,所以Hinton等人提出了Dropout概念,提高网络泛化能力防止了过拟合发生。但是GAP是另外方式避免全连接层的处理,直接通过全局池化+softmax进行分类,它的优点是更加符合卷积层最后的处理,另外一个优点是GAP不会产生额外的参数,相比全连接层的处理方式,降低整个计算量,此外全局池化还部分保留来输入图像的空间结构信息,所以全局池化在有些时候会是一个特别有用的选择。
- avg_pool2d 代码原理
【模型训练相关】
优化器SGD
随机梯度下降(stochastic gradient descent)
1 | optimizer = optim.SGD(net.parameters(), lr=0.01, weight_decay=1e-6, momentum=0.9, nesterov=True) |
nn.sequential
Pytorch 容器之 nn.Sequential
nn.Sequential 是一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
在初始化函数 init 中,首先是 if 条件判断,如果传入的参数为 1 个,并且类型为 OrderedDict,通过字典索引的方式将子模块添加到 self._module 中,否则,通过 for 循环遍历参数,将所有的子模块添加到 self._module 中。
nn.Conv2dl
pytorch之torch.nn.Conv2d()函数详解
【PyTorch学习笔记】17:2D卷积,nn.Conv2d和F.conv2d
nn.Conv2d:对由多个输入平面组成的输入信号进行二维卷积

【模型融合】
nn.ReLU(inplace=True)
将输入小于0的值幅值为0,输入大于0的值不变。
inplace=true 选择是否将得到的值计算得到的值覆盖之前的值。节省内存。
nn.MaxPool2d(kernel_size=2, stride=2),
在由多个输入通道组成的输入信号上应用2D max池。
【学习笔记】torch.nn.MaxPool2d参数解释
np.linspace()
np.linspace主要用来创建等差数列。
1 | numpy.linspace(start, stop, num=50, endpoint=True, retstep=False, dtype=None, axis=0) |
开始值,结束值,样本数。
【导入模型】
model.train()/eval()
model.train()和model.eval()的区别主要在于Batch Normalization和Dropout两层。
区别
训练集在train下运行,验证集和测试集都在eval下运行
with torch.no_grad()
pytorch中with torch.no_grad():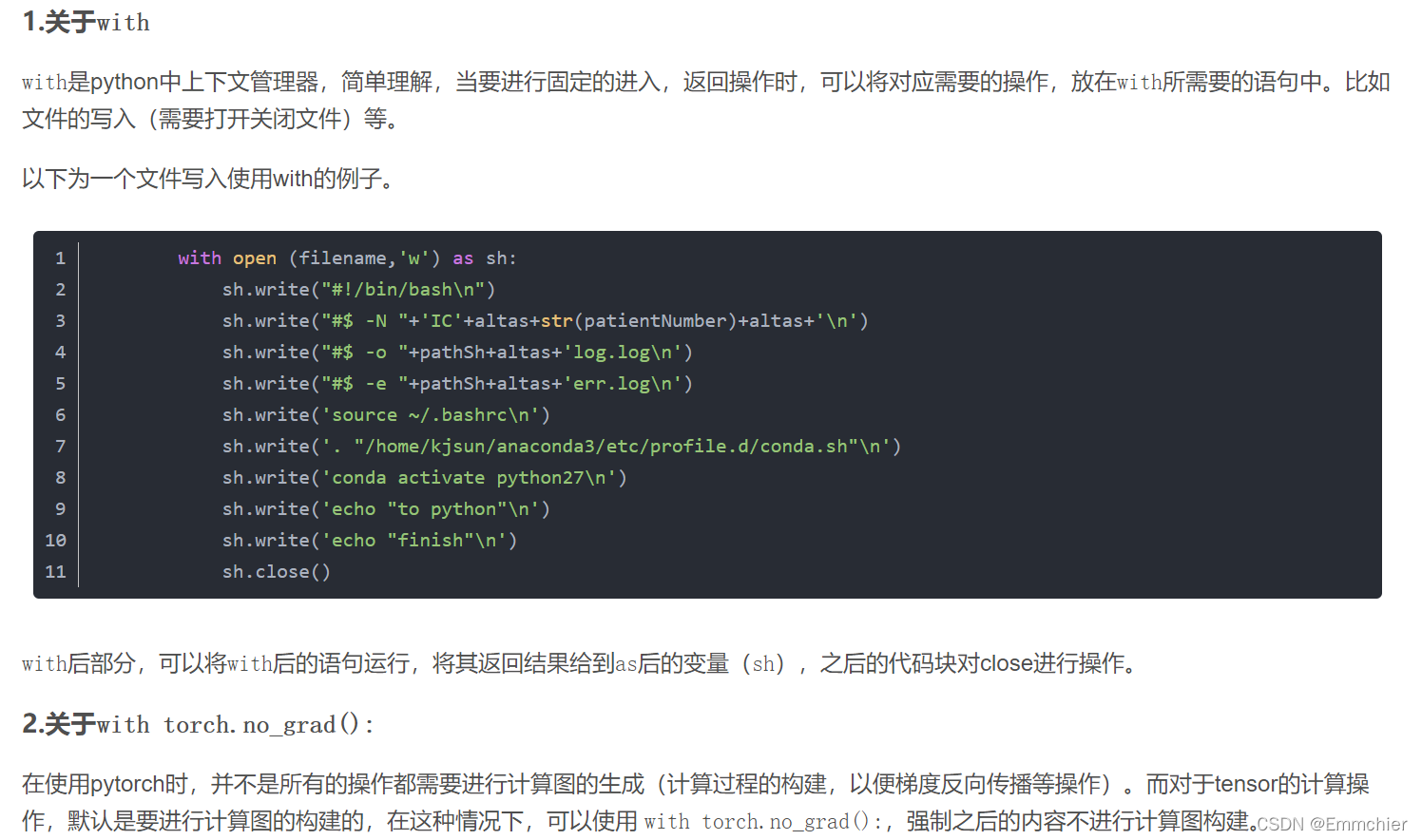

好像可以减少内存开销?
load_state_dict
torch.load_state_dict()函数就是用于将预训练的参数权重加载到新的模型之中
debug
1.TypeError: ‘CNN2d_classifier_xiao’ object is not subscriptable
——索引对象不支持索引
2.
3. Can’t get attribute ‘cnn2d_xiao_merge’ on <module ‘main‘

【优化模型】
优化模型参数


指定训练层
【数据特征提取】
相似度
reference
pytorch基础
- torch.mm与torch.bmm前者实现矩阵乘法,后者实现批量矩阵乘法
- torch.div() 说明: 张量和标量做逐元素除法或者两个可广播的张量之间做逐元素除法
- torch.norm() 返回所给定tensor的矩阵范数或向量范数,所谓范数也就是把一个高纬度的东西,压缩成为一个大于等于零的数,用以估算这里东西的大小(幅度)
- np.eye()的函数,除了生成对角阵外,还可以将一个label数组,大小为(1,m)或者(m,1)的数组,转化成one-hot数组。
- 【np.random.multivariate_normal】根据均值和协方差矩阵的情况生成一个多元正态分布矩阵
- numpy.linalg模块包含线性代数的函数。使用这个模块,可以计算逆矩阵、求特征值、解线性方程组以及求解行列式等。
- pickle.dump(obj, file, [,protocol]) 注释:序列化对象,将对象obj保存到文件file中去。参数protocol是序列化模式,默认是0
- torch.nn.DataParallel()–多个GPU加速训练
Tqdm是Python进度条库,可以在Python长循环中添加一个进度提示信息- from numpy import * : 这是导入了numpy模块的每个类,可以直接使用类,无需句点表示法
- torchvision数据集下载
import torchvision
train_set=torchvision.datasets.CIFAR10(root=”./dataset”,train=True,transform=dataset_transfrom,download=True)
test_set=torchvision.datasets.CIFAR10(root=”./dataset”,train=False,transform=dataset_transfrom,download=True)
torchvision.datasets.ImageFolder 返回训练数据与标签..

pytorch学习笔记七:torchvision.datasets.ImageFolder使用详解
pytorch提供两种数据集: Map式数据集 Iterable式数据集。其中Map式数据集继承torch.utils.data.Dataset,Iterable式数据集继承torch.utils.data.IterableDataset。
一个(3,3,64,32)的卷积核意思是:卷积核高度、卷积核宽度、输入通道数、输出通道数 具体意思是:32个64通道数的3*3的卷积核和输入进行卷积 输出32个卷积结果。

torch.cat(): 函数目的: 在给定维度上对输入的张量序列seq 进行连接操作。
torch.utils.data.DataLoader类…作用:是加载数据的核心,返回可迭代的数据。PyTorch中数据读取的一个重要接口是torch.utils.data.DataLoader,该接口定义在dataloader.py脚本中,只要是用PyTorch来训练模型基本都会用到该接口。该接口主要用来将自定义的数据读取接口的输出或者PyTorch已有的数据读取接口的输入按照batch size封装成Tensor,后续只需要再包装成Variable即可作为模型的输入,因此该接口有点承上启下的作用,比较重要。torch.utils.data包详解
torch.view() 改变tensor的形状 将一个2×2的张量变为1×4,就是通过view(1,4),1行4列。如果改为view(4,1),就会变为4×1的tensor,参数-1表示自适应,比如长度4的向量,view(-1,1),就相当于view(4,1)。有时候会出现torch.view(-1)或者torch.view(参数a,-1)这种情况。则-1参数是需要估算的。


target.view(-1,1)就是一列Pytorch中的view函数nn.conv2d()

permute() torch中permute()函数用法
torch.gather()的定义非常简洁 定义:从原tensor中获取指定dim和指定index的数据/.用途:方便从批量tensor中获取指定索引下的数据,该索引是高度自定义化的,可乱序的
dataloader—-numworker…https://blog.csdn.net/qq_36044523/article/details/118914223
os.getcwd() 方法用于返回当前工作目录。
save 图片学习日志(十四):Python之图片读取显示和保存
def main(args):
name_list = os.listdir(args.image_path)
for name in name_list:
img_path = os.path.join(os.getcwd(),’demo/inputs’,name)
image = plt.imread(img_path)
image_crop = image[0:300,0:300]
plt.imsave(img_path.replace(‘inputs’,’output’),image_crop)
- random.randint(0, 1)产生指定范围内的随机整数,包括边界
pytorch bug
- RuntimeError: Given groups=1, weight of size [24, 3, 3, 3], expected input[100, 32, 32, 3] to have 3 channels, but got 32 channels instead ——————torch和keras处理图片的维度顺序有所不同,torch需要将维度放在最前面,用permute()改变维度顺序写pytroch代码过程中遇到的错误
Cuda
Densenet3

nn.CrossEntropyLoss()
模型的损失函数





其中y_i是one_hot编码后的数据标签,NLLLoss()得到的结果即是y_i与logsoftmax()激活后的结果相乘再求均值再取反。(实际在用封装好的函数时,传入的标签无需进行one_hot编码)该损失函数结合了nn.LogSoftmax()和nn.NLLLoss()两个函数。它在做分类(具体几类)训练的时候是非常有用的。在训练过程中,对于每个类分配权值,可选的参数权值应该是一个1D张量。当你有一个不平衡的训练集时,这是是非常有用的。
交叉熵主要是用来判定实际的输出与期望的输出的接近程度,为什么这么说呢,举个例子:在做分类的训练的时候,如果一个样本属于第K类,那么这个类别所对应的的输出节点的输出值应该为1,而其他节点的输出都为0,即[0,0,1,0,….0,0],这个数组也就是样本的Label,是神经网络最期望的输出结果。也就是说用它来衡量网络的输出与标签的差异,利用这种差异经过反向传播去更新网络参数。



