
Transformer
[Public, Approved] Intro to Transformers - Google Slides
目前,主流的多模态大模型大多以Transformer为基础。Transformer是一种由谷歌在2017年提出的深度学习模型,主要用于自然语言处理(NLP)任务,特别是序列到序列(Sequence-to-Sequence)的学习问题,如文本生成。Transformer彻底改变了之前基于循环神经网络(RNNs)和长短期记忆网络(LSTMs)的序列建模范式,并且在性能提升上取得了显著成效。Transformer结构如下图所示:
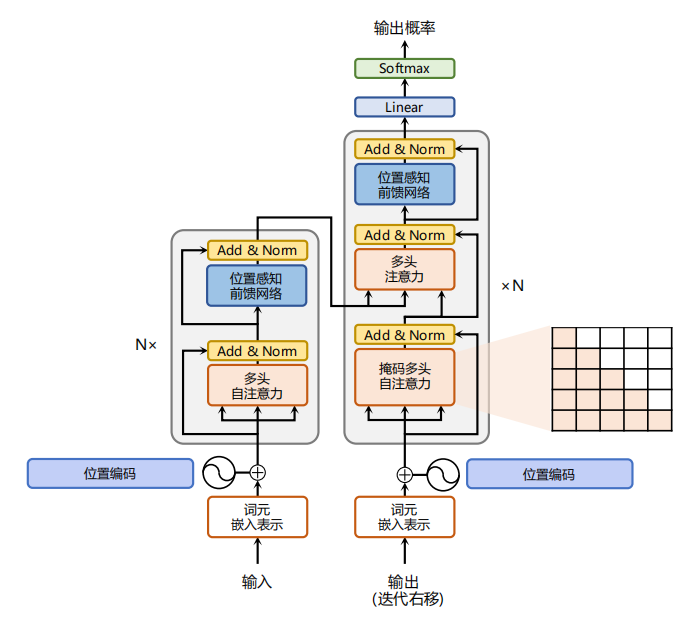
Transformer的核心构成包括:
自注意力机制(Self-Attention Mechanism):Transformer模型摒弃了传统RNN结构的时间依赖性,通过自注意力机制实现对输入序列中任意两个位置之间的直接关联建模。每个词的位置可以同时关注整个句子中的其他所有词,计算它们之间的相关性得分,然后根据这些得分加权求和得到该位置的上下文向量表示。这种全局信息的捕获能力极大地提高了模型的表达力。
多头注意力(Multi-Head Attention):Transformer进一步将自注意力机制分解为多个并行的“头部”,每个头部负责从不同角度对输入序列进行关注,从而增强了模型捕捉多种复杂依赖关系的能力。最后,各个头部的结果会拼接并经过线性变换后得到最终的注意力输出。
位置编码(Positional Encoding):由于Transformer不再使用RNN的顺序处理方式,为了引入序列中词的位置信息,它采用了一种特殊的位置编码方法。这种方法对序列中的每个位置赋予一个特定的向量,该向量的值与位置有关,确保模型在处理过程中能够区分不同的词语顺序。
编码器-解码器架构(Encoder-Decoder Architecture):Transformer采用了标准的编码器-解码器结构,其中,编码器负责理解输入序列,将其转换成高级语义表示;解码器则依据编码器的输出,结合自身产生的隐状态逐步生成目标序列。在解码过程中,解码器还应用了自注意力机制以及一种称为“掩码”(Masking)的技术来防止提前看到未来要预测的部分。
残差连接(Residual Connections):Transformer沿用了ResNet中的残差连接设计,以解决随着网络层数加深带来的梯度消失或爆炸问题,有助于训练更深更复杂的模型。
层归一化(Layer Normalization):Transformer使用了层归一化而非批量归一化,这使得模型在小批量训练时也能获得良好的表现,并且有利于模型收敛。
面试
- Transfomer结构介绍一下
- 对Q, K, V的理解?
- 对多头注意力中多头的理解?为什么用多头注意力机制,优势在哪里
- BERT的预训练过程讲一下。
- BERT做MASK的策略?(取15%的词进行计算损失;80%掩码,10%替换为随机词,10%保持不变)
- BERT的Embedding?(三个)
- BERT为什么使用LayerNorm而不使用BatchNorm
- Transformer做句子生成怎么做?
- 注意力计算
- attention里面的softmax和普通的softmax有什么不同
- attention里面q和k的转置的乘积结果除以根号k,k是什么?
ans
Transformer
Transformer结构介绍
- 回答:Transformer由编码器和解码器组成。编码器由多个相同的层叠加而成,每层包括自注意力机制和前馈神经网络。解码器也由多个相同的层叠加而成,每层包括自注意力机制、编码器-解码器注意力机制和前馈神经网络。
对Q, K, V的理解
- 回答:Q(Query)、K(Key)和V(Value)是注意力机制中的三个矩阵。Q代表查询向量,K代表键向量,V代表值向量。注意力机制通过Q和K的点积计算相似度,决定V的加权平均。
对多头注意力中多头的理解及优势
- 回答:多头注意力通过并行的多个注意力头捕捉不同子空间的信息,提高模型对特征的表达能力和稳定性。相比单头注意力,多头注意力更能捕捉复杂的模式和长距离依赖。
BERT
BERT的预训练过程
- 回答:BERT通过Masked Language Model(MLM)和Next Sentence Prediction(NSP)进行预训练。MLM随机遮盖输入文本中的一些词,然后预测它们;NSP预测两个句子是否连续。
BERT做MASK的策略
- 回答:BERT的MASK策略是取15%的词进行计算损失,其中80%用[MASK]替换,10%替换为随机词,10%保持不变。
BERT的Embedding
- 回答:BERT的Embedding包括词嵌入(Word Embeddings)、位置嵌入(Position Embeddings)和分段嵌入(Segment Embeddings)。
BERT为什么使用LayerNorm而不使用BatchNorm
- 回答:LayerNorm对每个样本独立标准化,适用于序列模型;而BatchNorm依赖于批量数据,在变长序列中效果不佳。
Transformer句子生成
- Transformer做句子生成
- 回答:使用解码器部分生成句子。解码器逐步生成每个词,通过注意力机制和前面生成的词预测下一个词,直到生成结束符。
注意力计算
attention里面的softmax和普通的softmax有什么不同
- 回答:attention中的softmax作用在Q和K的点积结果上,进行归一化处理,使得所有注意力权重之和为1。普通softmax用于分类任务,对输入进行指数归一化。
attention里面q和k的转置的乘积结果除以根号k,k是什么?
- 回答:k是Q和K的向量维度。除以根号k用于缩放,防止点积结果过大导致梯度消失,提高训练稳定性。
介绍
一文读懂 Transformer 神经网络模型 (qq.com)
【Transformer】10分钟学会Transformer | Pytorch代码讲解 | 代码可运行
【Huggingface Transformers】保姆级使用教程—上
- Transformers implement an attention-based encoder-decoder architecture for sequence analysis. Attention mechanisms [32] learn to aggregate information from the entire sequence,By stacking attentional layers which scan the sequence, Transformers generate a position and context aware representations. This method was shown to outperform recurrent neural networks (RNNs) and LSTMs for various sequence-based problems in Natural Language Understanding and Computer Vision, achieving state-of-the-art performance
- , the transformer model in the present study allows one to traverse the time series arbitrarily, since all the contextual relationships are calculated in parallel. When the attention mask is defined, the transformer model can search for connections among the features in the time series both in the direction from past to future, as well as in the opposite direction from future to past, according to the trained attention matrix. ——Using attention blocks, the transformer directly focuses on predicting the intensity of the gain/loss of the feature during the feed-forward phase based on the context found during the learning process. Two-dimensional convolutional networks work directly on the principle of the image classifier, and thus learn to recognize hidden patterns in signal frames and predict activities from them. The transformer model is a universal architecture used similarly to convolutional neural networks in NLP, vision, or signal processing tasks.当前的手稿涉及深度神经网络直接应用于来自传感器的信号的归一化时间序列。这项研究采用了一种完全基于注意力机制的流转时长序列的替代方法,称为变压器。变压器模型直接专注于使用注意力机制来寻找特征之间的时间序列中的相关性,并允许时间序列计算的大规模并行化,这与连续迭代时间序列的递神经归网络相比是不同的。变压器的另一个优点是时间序列中特征之间的更长路径长度,这允许更准确地学习长时间序列中的上下文,这是Vaswani等人提出的断言。[34]。计算速度以及预测准确性是处理人类活动的关键要素,其中预测可以直接在移动设备上执行。sequence-to-sequence方法用于预测活动[35],其中考虑来自变压器输出的所有时间步长并为其分配活动指定。这样,可以将活动分配给用户在测量来自移动设备的实时值时所采取的每个时间步长。——视觉变压器模型的例子已经展示了变压器模型如何有效地取代现有的循环和卷积神经网络。视觉变压器模型以图像的形式处理信号,这支持了这样一个假设,即它也可以处理来自传感器(如加速度计或陀螺仪)的一维时间序列信号。进一步提出的用于人类活动识别的变压器模型直接基于视觉变压器模型架构[43],然而,其中信号作为输入直接馈入编码器块,同时添加的信息确定信号时间序列中特征的位置。用于人类活动识别的变压器模型以sequence-to-sequence模式运行,并为每个时间序列特征预测类,见图1。优点是,如果一个时间序列中有几个连续的类,这些类可以很容易地识别,变压器不限于整个时间序列中属于一个类的特征。所有完全连接的层都使用均方差为0.02的截断正态分布进行初始化,如BEIT[44]中所示。在信号作为输入馈送到神经网络之前,它会通过一个归一化层,该层存储从训练数据中获得的均值和方差,并将输入调整为0.0均值和1.0均方差的值。这种解决方案的优点是,当模型投入实际使用时,它已经包含了这些校准值,不需要以外部方式解决信号调整。该模型已经完全准备好在移动设备中实施,前提是测量的量在基本物理单元中,加速度计在m/s2中,陀螺仪在rad/s中。模型的输出层是线性的,在功能不太强大的设备上提供比使用softmax函数时更高的计算速度。原则上,预测活动对应的最大值也可以在应用softmax之前获得,它只在损失函数中的学习期间使用。这种形式在那里使用,由于使用对数的计算,因为它在输出处没有负数,就像线性层一样。
- Transformer 特征抽取器:Transformer 模型最早由谷歌在 2017 年提出,属于深度学习模型架构的一种,特点是在学习中引入了注意力机制。对比循环神经网络 (RNN)来看,Transformer 与 RNN 均对输入数据,如自然语言等,进行顺序处理,并主要应用于翻译和文本摘要等工作。但 Transformer 与 RNN 不同的是,Transformer 中的注意机制可以为输入序列中的任何字符提供上下文,因此可以一次处理所有输入,而不是一次只处理一个词。因此,与 RNN 相比,Transformer 可以实现更大规模的并行计算,大大减少了模型训练时间,使得大规模 AI 模型得以被应用。
- 是一种神经结构,它利用注意力通过一系列步骤对顺序数据进行并行处理。在每一步中,注意机制从前一步序列中选择和组合元素,以可微和5ot 约束的方式对序列中的每个位置形成新的表示。主要出现在自然语言处理 Q 领域,也已成功应用于各类问题。虽然 transformer 结合图形神经网络和语言模型,但 transformer 的运行时间和内存占用可以随着序列的长度二次扩展,导致 long-range 建模和线性注意力机制°被用作去解决效率问题。因此,无监督或自监督生成预训练变压器,然后是参数有效微调,被广泛使用。
- Transformer 解码模块是 GPT 模型的核心要建。从 Transformer 架构细节来看,核心是由编码模块和解码模块构成,而 GPT 模型只用到了解码模块。拆解模块来看,大致分为三层:前馈神经网络层、编码/解码自注意力机制层(Self-Attention)、自注意力机制掩码层。其中,自注意力机制层主要作用在于计算某个单词对于全部单词的权重(即 Attention),掩码层则需要在这一过程中帮助模型屏蔽位于计算位置右侧尚未出现的单词,最后输出的向量结果输入前馈神经网络,完成模型参数计算。
- BERT 模型在结构上是一个多层的双向 transformer 的 Encoder 模型,GPT 是由 12 个 Transformer 中的 Decoder 模块经修改后组成。相比来说,BERT 模型的核心优势在于自然语言理解,GPT 模型的核心优势在于自然语言生成
关键特点包括:
自注意力机制(Self-Attention): Transformer 使用了自注意力机制,使模型能够在输入序列中的不同位置关注不同程度的信息。这使得模型能够并行处理输入序列,提高了训练效率。
无需序列顺序: 传统的循环神经网络(RNN)和长短时记忆网络(LSTM)等在处理序列数据时需要按顺序逐步处理。而 Transformer 具有并行处理的能力,无需按顺序处理输入序列。
编码器-解码器结构: Transformer通常用于序列到序列的任务,例如机器翻译。它包含一个编码器(用于处理输入序列)和一个解码器(用于生成输出序列)。字向量加上 位置信息得到Encoder的输入 矩 阵。位置信息Positional Encoding是固定公式计算出来的,值 不会改变,每次有数据来了直接加上 Positional Encoding矩阵就行. 为什 么需要在Embedding加上Positional Encoding?与RNN相比,RNN是一个 字一个字的输入,自然每个字的顺序关 系信息就会保留下来。但在Encoder 中,一个句子的每一个字(词)是并行 计算的(下一节解释),所以我们在输 入的时候需要提前引入位置信息。 思想:先计算出第一个字与句 子中的每一个字的注意力分数(包括第 一个字),再用计算出的注意力分数乘 以对应字的信息,然后加在一起,得到 的结果就是第一个字与句子中所有字的 加权和,依次更新每一个字与句子的注 意力信息。
多头注意力(Multi-Head Attention): 为了更好地捕捉不同层次的语义信息,Transformer中的注意力机制可以分为多个头。每个头学习关注输入序列的不同部分,最后进行合并。Multi-Head Attention,它与单头注意力不同的就 是把原来 Q,K,V 三个大矩阵拆分成8个 形状相同的小矩阵(在特征维度上拆 分),也就是8头注意力。 Add是用 了残差神经网络的思想,也就是把 Multi-Head Attention的输入的 a 矩 阵直接加上Multi-Head Attention的 输出 b 矩阵(好处是可以让网络训练的 更深。Layer Normalization和Batch Normalization的区别:Layer Normalization:是在一个句上的进行 归一化。Batch Normalization:是把 每句话的同一维度上的字看成一组做归 一化。 ————Encoder 的 Multi-Head Attention 的 结构和 Decoder 的 Multi-Head Attention 的结构也是一样的,只是 Decoder 的 Multi-Head Attention 的 输入来自两部分,K,V 矩阵来自 Encoder的输出,Q 矩阵来自 Masked Multi-Head Attention 的输出
位置编码: 由于自注意力机制无法直接捕捉序列中元素的顺序信息,Transformer 使用位置编码来注入序列元素的位置信息。
mask的作用
- 第一种情况:mask作用是去掉 没有意义的字,例如在中文数据集预 处理的时候,中文字有几万个,但是 常用只有几千个,为了较小模型复杂 度和增加网络的泛化能力,就需要把 一些生僻字用padding替换。其次为 了并行计算,保证每一个句子长度一
单头注意力机制 和 多头注意力 机制的区别? 区别:求注意力分数时,单头是整行求 softmax,多头是分段求softmax
任务
- Transformers 中有许多不同的架构可 用,每一种架构都围绕着处理特定任务 而设计,清单: *Model (retrieve the hidden states) *ForCausalLM *ForMaskedLM *ForMultipleChoice *ForQuestionAnswering *ForSequenceClassification *ForTokenClassification and others
变种/类似
由于其创新性的结构和优越的性能,Transformer不仅在自然语言处理领域广泛应用,还在其他领域如图像处理等取得了成功。其中,BERT(Bidirectional Encoder Representations from Transformers)和GPT(Generative Pre-trained Transformer)等模型是 Transformer 模型的重要变种。
Transformer 和 autoencoder 是两种不同的神经网络架构,但它们都属于深度学习领域,并在不同的应用中发挥重要作用。
共同点:
- 特征学习: 两者都具有学习数据中有用特征的能力。Autoencoder 通过编码器学习数据的低维表示,而 Transformer 通过注意力机制在输入序列中学习有用的特征。
- 无监督学习: Autoencoder 是一种无监督学习模型,而 Transformer 通常用于监督和无监督学习任务,如机器翻译和语言建模。
区别:
- 架构设计: Autoencoder 通常由编码器和解码器组成,其中编码器将输入数据映射到潜在表示,解码器将潜在表示还原为原始数据。而 Transformer 包含编码器和解码器,但其结构更加复杂,引入了自注意力机制,允许并行处理序列数据。
- 任务应用: Autoencoder 主要用于数据降维、特征学习和生成模型。它在图像去噪、数据压缩等方面有广泛应用。而 Transformer 在自然语言处理领域表现出色,特别是在机器翻译、文本生成等任务中取得了显著成果。
itransformer
- iTransformer讲了一个什么改进模型的思路?-赤页-稍后再看-哔哩哔哩视频 (bilibili.com)
- 有多个模态signal,transformer是竖着切某个时间点,每个时间点的多个变量,给token,但失去了前后历史信息,itransformer横着将整个signal放进去, crosstransformer用patch块状的形式
