
method-多模态
太全了!多模态深度学习的综述! (qq.com)
IEEE. Trans. Pattern. Anal. Mach. Intell. |从视觉到文本多模态数据融合综述 (qq.com)
模态
人工智能 - 一站式解读多模态——Transformer、Embedding、主流模型与通用任务实战(上) - 百度飞桨 - SegmentFault 思否
上述的大多多模态模型结构可以总结为五个主要关键组件,具体如下图所示:
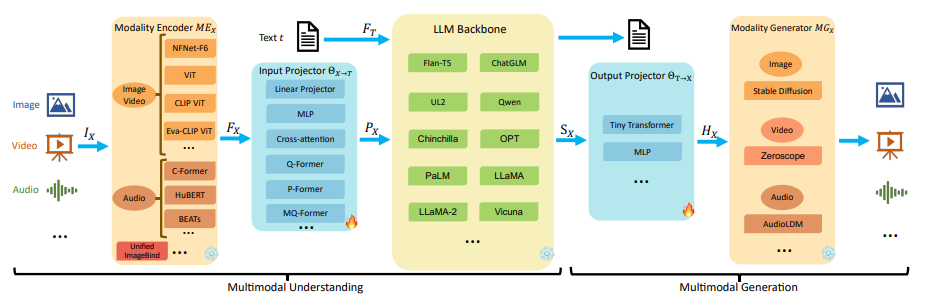
模态编码器(Modality Encoder, ME):图像编码器(Image Encoder)、视频编码器(Video Encoder)、音频编码器(Audio Encoder)
输入投影器(Input Projector, IP):线性投影器(Linear Projector)、多层感知器(Multi-Layer Perceptron, MLP)、交叉注意力(Cross-Attention)、Q-Former等
大模型基座(LLM Backbone):ChatGLM、LLaMA、Qwen、Vicuna等
输出投影器(Output Projector, OP):Tiny Transformer、Multi-Layer Perceptron (MLP)等
模态生成器(Modality Generator, MG):Stable Diffusion、Zeroscope、AudioLDM
按上述五部分结构对经典多模态模型进行总结,结果如下:

以VIT为基础视觉预训练可以通过Transformers模型对视觉进行有效表征,逐渐成为视觉信息编码的主流手段。此部分主要梳理以VIT为延伸的预训练和多模态对齐工作,具体分类如下:
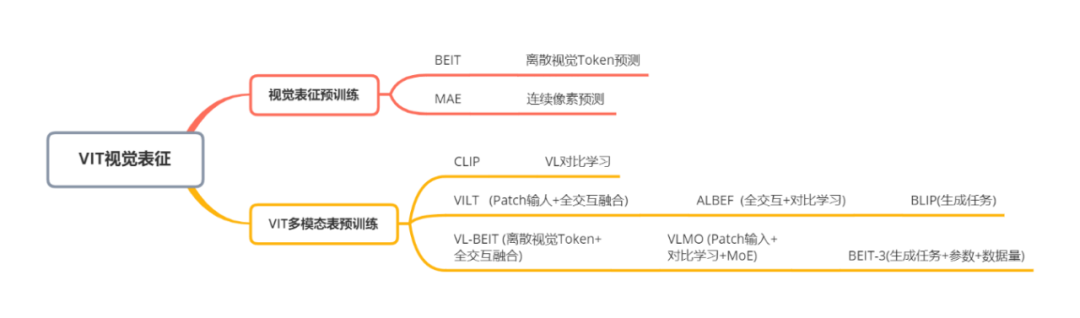
上述多模态预训练模型发展关系如下:
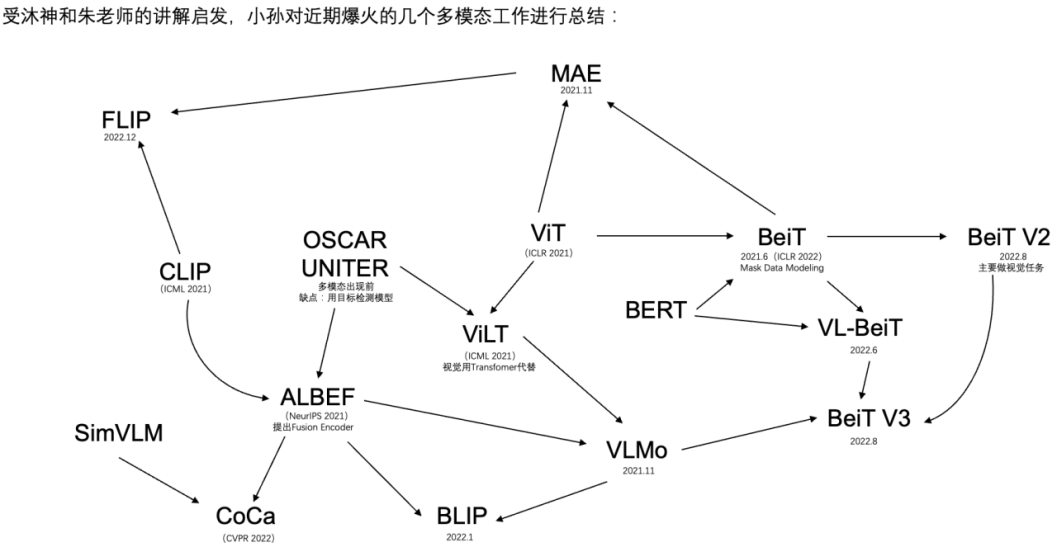
embedding
1.文本转 Embedding
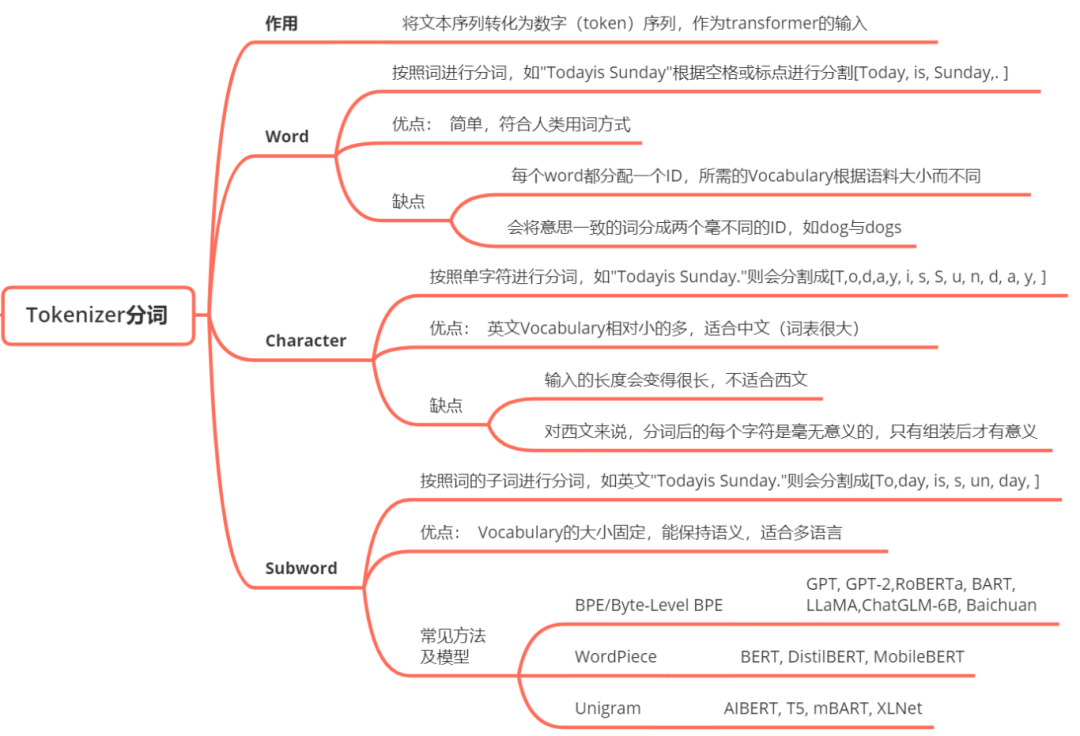
Tokenization:
Tokenization也称作分词,是把一段文本切分成模型能够处理的token或子词的过程,通常会使用BPE或WordPiece的分词算法,有助于控制词典大小的同时保留了表示文本序列的能力。Tokenization的知识点总结如下:
Embedding:
Embedding将token或子词用映射到多维空间中的向量表示,用以捕捉语义含义。这些连续的向量使模型能够在神经网络中处理离散的token,从而使其学习单词之间的复杂关系。经典的文本转Embedding可采用 Tramsformer(bert) 模型
具体步骤:
- 输入文本:“thank you very much”
- Tokenization后: [“thank”, “you”, “very”,“much”]
- Embedding:假设每个token被映射到一个2048维的向量,“thank you very much”被转换成4*2048的embeddings
2.图像转换Embedding
图像转Emdedding一般采用Vit Transformer模型。首先,把图像分成固定大小的patch,类比于LLM中的Tokenization操作;然后通过线性变换得到patch embedding,类比LLM中的Embedding操作。由于Transformer的输入就是token embeddings序列,所以将图像的patch embedding送入Transformer后就能够直接进行特征提取,得到图像全局特征的embeddings。具体步骤如下:

图像预处理:
- 输入图像大小:224x224像素,3个颜色通道(RGB)+ 预处理:归一化,但不改变图像大小图像切分:
- 假设每个patch大小为14x14像素,图像被切分成(224/14) × (224/14) =256个patches 线性嵌入:
- 将每个14x14x3的patch展平成一个一维向量,向量大小为 14×14×3=588
- 通过一个线性层将每个patch的向量映射到其他维的空间(假设是D维),例如D=768 , 每个patch被表示为一个D维的向量。最后,由于Transformer内部不改变这些向量的大小,就可以用256*768的embeddings表示一张图像。
难点
- 多模态数据联合预训练的典型方法经常遇到模态数据冲突和整合新知识成本高的问题
方法
多模态应用分类为两个主要方向:辨别性和生成性应用
结合多模态数据进行分类任务是一个常见的挑战,特别是在处理不同类型的数据,如文本、图像、音频等。以下是一些常见的方法:
- 融合层级模型(Multimodal Fusion Models):
- 建立多个模态数据的独立模型,然后通过一个融合层将它们的表示整合在一起。这个融合可以是简单的拼接、加权求和、注意力机制等。这样的模型通常包括一个用于每个模态的子模型和一个用于融合的主模型。
- 多模态注意力(Multimodal Attention):
- 使用注意力机制来赋予不同模态数据不同的重要性。这可以帮助模型在处理多模态输入时更好地关注关键信息。
- 共享表示学习(Shared Representation Learning):
- 尝试学习一个共享的表示,使得不同模态数据在共享空间中有意义的对应。这通常涉及到使用联合训练或对抗性训练来确保学到的表示能够更好地适应不同模态。
- 循环神经网络(Recurrent Neural Networks,RNNs):
- 对于时序性的多模态数据,可以使用RNNs来处理序列信息。这对于处理时间序列、视频等数据类型特别有效。
- 特征融合(Feature Fusion):
- 直接融合提取的特征。这可以通过将来自不同模态的特征连接在一起,然后馈送到分类器中。
- 迁移学习(Transfer Learning):
- 如果某些模态的数据量较小,可以通过迁移学习从其他大数据模态中学到的知识,然后迁移到小数据模态上。
- Ensemble Methods:
- 将多个单模态模型的输出进行组合,例如投票、平均值等。
- 生成对抗网络(Generative Adversarial Networks,GANs):
- 使用生成模型来生成缺失的模态数据,以增加数据的丰富性。
选择合适的方法通常取决于你的数据特性、任务需求和可用的计算资源。在实践中,一些方法可能需要更多的调整和实验来找到最佳配置。
- 使用生成模型来生成缺失的模态数据,以增加数据的丰富性。
对于多模态自编码器,分类层通常位于编码器之后,解码器之前。
输入为多模态数据,怎么通过encoder和decoder进行分类?
训练
多模态大型语言模型的训练流程主要分为两个阶段:多模态预训练(MM PT)和多模态指令调优(MM IT)。以下为两阶段介绍:
(1)多模态预训练:
目标:预训练阶段的目标是通过训练输入和输出投影器(IP和OP)来实现不同模态之间的对齐,以便LLM主干能够有效地处理多模态输入。
数据集:通常使用X-Text数据集,包含图像-文本(Image-Text)、视频-文本(Video-Text)和音频-文本(Audio-Text)对,以及交错的图像-文本语料库等。
优化:训练过程中,主要优化的是输入和输出投影器的参数,以最小化条件文本生成损失。通常涉及到将模态编码器的输出特征与文本特征对齐,生成的对齐特征作为LLM主干的输入。
(2)多模态指令调优:
目标:指令调优阶段的目标是通过指令格式化的数据集对预训练的MM-LLM进行微调,以提高模型遵循新指令的能力,从而增强其在未见任务上的性能。
方法:指令调优的训练方法可以分为监督式微调(SFT)和基于人类反馈的强化学习(RLHF)。SFT将PT阶段的数据转换为指令感知格式,而RLHF则依赖于对模型响应的人类反馈进行进一步微调。
数据集:使用的数据集通常包括视觉问答(VQA)、指令遵循任务等,数据集结构可以是单轮问答或多轮对话
监督学习
- 一种可能的方法是在获取各自特征空间的数据表示后建立映射,可以被视为一种两阶段方法,称为“各模态领域内的表示学习 + 模态之间的映射”,通常第一阶段的特征提取使用固定的骨干模型。另一种解决多模态表示问题的方式是以端到端的方式为给定的数据对学习统一的表示,自由优化特征提取的骨干模型。
- 对于第一种方法,Liu 等人利用现有的从视觉内容中预训练的语义嵌入,并提出了协作专家模型来聚合多模态信息。Wang 等人关注视频和文本表示的全局局部序列对齐。对于第二种方法,提出了学习两分支神经网络来匹配文本和图像数据。在音频-视觉领域,通过“音频-视觉对应”学习任务学习互相表示。
非监督学习
- “无监督”通常指网络在没有人类监督的情况下训练,“弱监督”描述的是监督可能是嘈杂、有限或不精确的情况;“自监督”用于描述模型从输入的一部分中学习另一部分的情况。
- 非监督学习设置的基本思想依赖于多模态配对数据之间固有的同步性质。
- 研究团队可以将大规模预训练视为特定类型的多模态表示学习,因为预训练的主要目标是学习一个联合和统一的跨模态表示,可以灵活地转移到其他领域或下游任务。
paper
- Vision + X: A Survey on Multimodal Learning in the Light of Data
- IEEE. Trans. Pattern. Anal. Mach. Intell. |从视觉到文本多模态数据融合综述 (qq.com)
- CVPR2024—重磅来袭!西工大团队提出通用多模态医学数据表示学习方法!持续自监督学习! (qq.com)
- ICML2023 清华大学、加州大学、麻省理工等高校联合提出——监督多模态学习中的单模态特征学习 (qq.com)
- [2312.03700] OneLLM: One Framework to Align All Modalities with Language (arxiv.org)多模态大语言模型(MLLM)因其强大的多模态理解能力而获得了显著的关注。然而,现有的作品严重依赖于模态特定的编码器,这些编码器通常在架构上有所不同,并且仅限于常见的模态。在本文中,我们提出了OneLLM,这是一种使用统一框架将八种模态与语言对齐的MLLM。我们通过统一的多模态编码器和渐进式多模态对齐管道来实现这一点。详细地说,我们首先训练一个图像投影模块,将视觉编码器与LLM连接起来。然后,我们通过混合多个图像投影模块和动态路由来构建通用投影模块(UPM)。最后,我们逐步将更多的模式与UPM对齐到LLM。为了充分利用OneLLM在以下指令中的潜力,我们还策划了一个全面的多模态指令数据集,包括来自图像、音频、视频、点云、深度/法线图、IMU和功能磁共振成像大脑活动的2M项。OneLLM在25个不同的基准上进行评估,包括多模态字幕、问答和推理等任务,在这些任务中,它提供了出色的性能。代码、数据、模型和在线演示可在https URL获得
idea
- 与任务无关的 image, video, point cloud, and audio. 多模态数据也能提升 Transformer 性能[[多模态-CVPR2024 -Multimodal PathwayMultimodal Pathway]] ——视频模态的大量数据提升 earset 时序数据(这篇没有时序)和实验室的时序数据。
- 文生图生成数据集来训练。CapS-Adapter。与 Baseline 方法 SuS-X 相比。作者主要将这些显著的改进归因于数据集对支持集中图像特征质量的提高敏感度。_Caps_中图像特征的优越质量主要是因为这些数据集中的图像类别在像 Stable Diffusion 这样的文本到图像生成模型的预训练中没有被广泛表示,这些模型缺乏关于这些类别的足够先验知识。因此,支持集图像的生成在很大程度上依赖于输入提示。_Caps_利用基于标题的提示,与 SuS-X 使用的更简单的 GPT-3 生成或手动提示相比,这些提示提供了分布更均匀、更丰富和更多样化的实例级信息,从而更好地指导支持集图像的生成过程。 清华大学提出CapS-Adapter | 利用CLIP的单模态和跨模态优势,通过使用多模态支持集提高了预测准确性! (qq.com) github https://github.com/WLuLi/CapS-Adapter
- 37项SOTA!全模态预训练范式MiCo:理解任何模态并学习通用表示|港中文&中科院-腾讯云开发者社区-腾讯云 (tencent.com)
| paper | content | 优点 | link |
|---|---|---|---|
| CapS-Adapter | 1. 构建基于标题的支持集 (利用文生图模型)2.多模态- Adapter | 2 | |
| Mico | 1. 全模态编码器 (ViT) 提取多模态特征,然后使用文本编码器提取文本特征 2. 共享一套位置编码,以构建跨越不同模态的融合上下文关系 | 3 | |
