
Generative AI
- 什么是生成式 AI?| 生成式 AI 完整指南 | Elastic
- 解码GAI,TMT企业如何拥抱GAI转型浪潮? | 德勤中国 | 科技、传媒和电信行业 (deloitte.com)
- 解释:生成式 AI |麻省理工学院新闻 |麻省理工学院 (mit.edu)
- 生成式人工智能(AIGC)研究综述: 从Google Gemini到OpenAI Q*-腾讯云开发者社区-腾讯云 (tencent.com)
- 万字综述:生成式AI技术栈全景图 - 知乎 (zhihu.com)>
- 生成式AI:六大公司九大模型综述-百度开发者中心 (baidu.com)
- 各种生成模型:VAE、GAN、flow、DDPM、autoregressive models-CSDN博客
- 一文看尽所有生成式模型:9大类别21个模型全回顾! - 知乎 (zhihu.com)
- 什么是生成式人工智能?— 生成式人工智能详解 — AWS (amazon.com)
- 机器学习中的判别式模型和生成式模型 - 知乎 (zhihu.com)
- Generative AI: What Is It, Tools, Models, Applications and Use Cases (gartner.com)
deep learning
- deep generative models
- deep discriminative models
- deep hybrid models
深度学习模型:生成式和判别式。
- 判别模型是一种类型的模型,用于对数据点进行分类或预测标签,判别模型通常在一个带标签的数据点的数据集上进行训练。它们学习数据点的特征和标签之间的关系,一旦判别模型被训练好,它可以用来预测新数据点的标签。生成模型根据现有数据的概率分布生成新的数据实例,基于学习到的概率分布,因此生成模型会生成新内容和。判别模型学习条件概率分布或者 Y 的概率(即我们的输出),给定 X(即我们的输入),比如给一张狗的图片,并将其分类为狗而不是猫,生成模型学习联合概率分布或者 X 和 Y 的概率,并预测这是一只狗的概率,然后可以生成一张狗的图片。总结一下,生成模型可以生成新的数据实例,而判别模型在不同类型的数据实例之间进行区分。
- 判别式和生成式是人为赋予的概念,之所以这么区分是因为两者属于不同的流派,对于同样的任务目标,它们的处理 (建模)方式是不同的。通常而言,判别式模型可认为是对条件概率 p (y|x) 建模;而生成式模型则是对联合概率 p (x, y)建模。判别式学习函数找不同类别的差异性,生成模型学习这个类别 y 和对应特征 x 一起出现的概率,哪个类别概率大就哪个。生成式模型实质上能学到关于数据分布和内在特性的更多信息,并且它能够生成某个类别的新实例。不仅仅是判断某物属 A or B,而是能够创造出属于 A or B 的某物
区分什么是通用人工智能和什么不是通用人工智能可以用一个非常简单的方法,当输出是一个数字或者一个类别,例如垃圾邮件或非垃圾邮件或者一个概率时,它不是通用人工智能;当输出的是自然语言,如语言或文本、图像或者音频视频时,它是通用人工智能。
- 生成式人工智能 (AI) 从现有数据中学习,然后生成具有类似特征的数据。例如,它可以生成文本、图像、音频、视频和计算机代码。
- 生成式 AI 是人工智能的一个分支,其核心是能够生成原创内容的计算机模型。通过利用大型语言模型、神经网络和机器学习的强大功能,生成式 AI 能够模仿人类创造力生成新颖的内容。这些模型使用大型数据集和深度学习算法进行训练,从而学习数据中存在的底层结构、关系和模式。根据用户的输入提示,生成新颖独特的输出结果,包括图像、视频、代码、音乐、设计、翻译、问题回答和文本。
我的理解
- 生成式 AI 是指可以根据输入生成图像、视频、代码、音乐、设计、翻译、问题回答和文本,而不仅仅是判别类别。包括 GAN、VAE、transformer、Diffusion 等等,其中 GAN、Diffusion 主要是生成图像,VAE 是图像、视频,Transformer 是文本、图像、语音等。
- 生成式模型是深度学习的一个派别,另一个是判别式模型。区别在于生成式模型是对联合概率建模,不仅是判别,还可生成某个类别的新实例。生成式模型包括自回归、自编码、GAN、朴素贝叶斯、KNN、混合高斯、HMM,判别式模型包括:线性回归、逻辑回归、支持向量机、决策树和随机森林等.
生成式 AI 相当于生成式模型的生成新实例的应用?
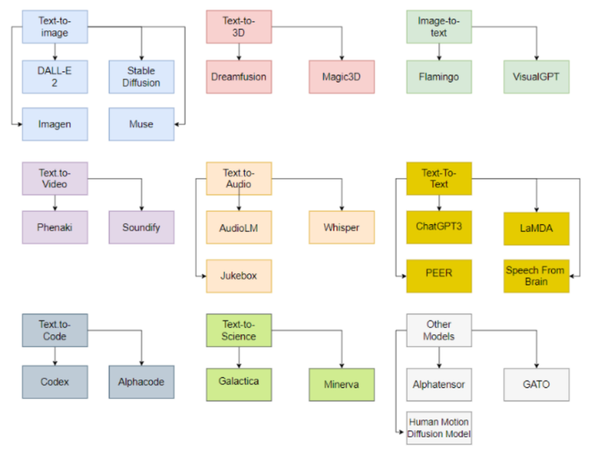
模型
- 递归式生成模型(Autoregressive Model)
递归式生成模型是一种基于条件概率的生成模型,能够生成与前面生成内容相关的后续内容。常见的递归式生成模型包括循环神经网络(RNN)和变换器(Transformer)等。递归式生成模型的缺点是无法同时考虑全局信息,因此容易出现局部不连贯的问题。 - 生成式对抗网络(Generative Adversarial Networks, GAN)
生成式对抗网络是一种基于对抗学习的生成模型,能够生成逼真的数据,如图像、音频等。GAN 主要包括生成器和判别器两个部分.GAN 的优点是能够生成高质量的数据,但其训练过程相对复杂,需要平衡生成器和判别器的性能,避免生成器落入局部最优解。
部分最常见的生成式 AI 模型包括:
- 生成式对抗网络 (GAN):GAN 由两个关键组件组成:生成器和鉴别器。生成器根据从训练数据中学习到的模式生成合成数据。鉴别器则充当鉴定人,评估所生成数据与真实数据相比的真实性,并决定数据的真假。训练过程将教会生成器生成更逼真的输出结果,而鉴别器则不断提高对真实数据和合成数据的区分能力。GAN 广泛应用于图像生成领域,并在创造异常逼真的视觉效果方面展现出了令人印象深刻的成果。GAN在生成细节方面表现较好,但训练难度较大
- 变分自动编码器 (VAE):- Variational Autoencoder.
- VAE 是可学习编码和解码数据的神经网络。编码器用于将输入数据压缩为一个低维表示(称为潜在空间)。同时,解码器用于从潜在空间重建原始数据。VAE 能够通过对潜在空间中的点进行采样,并将其解码为有意义的输出,从而生成新数据。这种方法在图像和音频合成方面尤为有用,因为可以通过对潜在表示的处理,生成多种多样且有创意的输出。VAE(变分自编码器)是一种基于概率图模型的生成式 AI 模型,其通过学习和推断数据隐含的潜在表示,能够生成新的数据。VAE 采用变分推理和重参数化技巧,能够实现高效的学习和推断。VAE 在图像、文本和音频等领域也有广泛的应用。. AE 在保持数据结构和生成质量方面表现较好,但推理时间较长
- 变分自动编码器(VAE)学习一种称为_潜在空间_的紧凑数据表示形式。潜在空间是数据的数学表示形式。可以将潜在空间视为唯一的代码,根据数据的所有属性来表示数据。例如,如果研究面部,则潜在空间包含代表眼睛形状、鼻子形状、颧骨和耳朵的数字。VAE 使用两个神经网络 — _编码器_和_解码器_。编码器神经网络将输入数据映射为潜在空间每个维度的均值和方差。该神经网络从高斯(正态)分布中生成随机样本。此样本是潜在空间中的一个点,表示输入数据的压缩简化版本。解码器神经网络从潜在空间中获取此取样点,然后将其重新构造回与原始输入相似的数据。使用数学函数衡量重新构造的数据与原始数据的匹配程度。
- 生成流模型、
- Diffusion Model
- 扩散模型通过对初始数据样本进行迭代性的受控随机更改来创建新数据。这些模型以原始数据为起点,然后加入细微的变化(噪点),逐渐使其与原始数据不那么相似。这种噪点经过仔细控制,以确保生成的数据保持一致性和真实性。在多次迭代中添加噪点之后,扩散模型反转该过程。反向去噪会逐渐消除噪点,从而产生与原始数据样本相似的新数据样本。
- Transformer 生成模型.
- 基于转换器的生成式人工智能模型建立在 VAE 的编码器和解码器概念之上。基于转换器的模型为编码器添加更多层,以提高理解、翻译和创意写作等文本式任务的处理性能。基于转换器的模型使用自注意力机制。在处理序列中的每个元素时,这些模型权衡输入序列中不同部分的重要性。另一个关键功能是这些人工智能模型实现_上下文嵌入_。序列元素的编码不仅取决于元素本身,还取决于其在序列中的上下文。
- 自注意力可以帮助模型在处理每个单词时将注意力集中在相关的单词上。为获取单词之间不同类型的关系,基于转换器的生成式模型采用称为_注意力头_的多个编码器层。每个头都学习关注输入序列的不同部分。这样,模型就可以同时考虑数据的各个方面。每个层还会对上下文嵌入进行优化。这些层使嵌入的信息更丰富,同时可获取从语法句法到复杂语义的所有内容。
- 大型语言模型 (LLM):像 ChatGPT(生成式预训练转换器)这类最常见类型的 LLM,都是基于大量文本数据训练出来的。这些复杂的语言模型使用了从教科书、网站到社交媒体帖文等多个领域的知识。它们利用转换器架构来理解并根据给定的提示生成连贯的文本。转换器模型是大型语言模型中最常见的架构。它由编码器和解码器组成,通过将给定提示转换为词元来处理数据,从而发现词元之间的关系。
扩散模型在生成 AI 空间中表现出令人印象深刻的能力。这些模型能够通过简单地使用文本提示来创建各种风格的图像,从逼真和未来主义到更多的艺术风格。
Unconditioned generation/conditioned generation
- From “Generative AI in Vision: A Survey on Models, Metrics and Applications”
- As the name suggests, unconditional generative models are trained to learn a target distribution and synthesize new samples without getting conditioned by any other input.
- On the contrary, conditional diffusion models take a prompt and some random initial noise and iteratively remove the noise to construct an image.
挑战
关键问题包括:
- 数据偏见:生成式 AI 模型依赖于它们训练所使用的数据。如果训练数据存在偏见或局限性,这些偏见就会在输出结果中反映出来。组织可以通过仔细限制训练模型所使用的数据,或使用符合自身需求的定制专用模型来缓解这些风险。
- 伦理方面的考虑:生成式 AI 模型创造逼真内容的能力引发了伦理方面的担忧,例如它对人类社会产生的影响,以及被滥用或操纵的可能性。确保以负责任且合乎伦理的方式使用生成式 AI 技术,将是一个持续存在的问题。
- 输出不可靠:众所周知,生成式 AI 和 LLM 模型会产生幻觉反应,当模型无法获取相关信息时,这一问题就会更加严重。这可能会导致向用户提供错误的答案或误导性信息,而这些信息听起来却真实可信。内容听起来越真实,识别出不准确的信息就越难。
- 领域特定性:缺乏对特定领域内容的了解是 ChatGPT 等这类生成式 AI 模型的一个常见局限。模型可以根据它们训练所使用的信息(通常是公开互联网数据)生成连贯且与上下文相关的回复,但它们通常无法访问特定领域的数据,也无法提供依赖于独特知识库(如组织的专有软件或内部文档)的答案。您可以通过提供对特定于领域的文档和数据的访问权限来最大限度地减少这些限制。
- 时效性:模型的新鲜程度取决于它们训练所用的数据。模型所能提供的回复是基于“特定时间点”数据的,而非实时数据。
- 计算要求:训练和运行大型生成式 AI 模型需要大量的计算资源,包括性能强大的硬件和大量的内存。这些要求可能会增加成本,并限制某些应用程序的可访问性和可扩展性。
- 数据要求:训练大型生成式 AI 模型还需要访问大量的语料数据,这些数据的存储可能非常耗时且成本高昂。
- 来源问题:生成式 AI 模型并不总是能确定所提取内容的来源,从而引发复杂的版权和归属问题。
- 缺乏可解释性:生成式 AI 模型通常像“黑盒”一样运作,这使得理解其决策过程变得特别困难。缺乏可解释性可能会阻碍信任并限制在关键应用领域的采用。
首先,作为近期火爆全球的新兴技术,其本身还存在一定的不成熟与监管漏洞。德勤总结以下9大主要风险:
- 偏差性:由于GAI依赖投喂的训练数据,若训练数据本身带有偏差性,如人口、种族等偏见,则输出结果也无法做到公平公正,因此仍需要人工监督与调整
- 成本:复杂模型的使用成本通常较高,大型模型的调整与运行成本甚至可以数万美元计,因此对于中小企业,借助第三方工具或许是更佳选择
- 使用道德:GAI的使用是否道德,取决于使用方式与使用目的。例如,在专利研究与学术发表时,AI的使用需要尤其关注其道德性
- AI幻象:GAI生成的内容通常看起来极具说服力且专业,然而,由于用户无法获得来源和引文,需要时刻对内容的正确性保持警惕,并认真进行调查和验证
- IP保护:若企业用第三方GAI应用,则需要尤其注意保护企业的机密数据安全,否则企业机密数据将有可能被用来进行二次训练,从而丧失其保密属性,影响企业竞争力
- 恶意行为:随着GAI的发展,对于安全性和客户信任的运维保护也愈发重要,企业应主动将网络恶意行为的风险进行管控
- 模拟性能:模型越大,输出质量越好,同时生成时间也越长,企业需要在二者中不断尝试,方可找到平衡
- 隐私:若使用云上服务的GAI提供商,数据可能面临隐私泄露与出境问题,需要考虑当地监管
- 规模限制:尽管基础模型在不断进步,其对可处理文档规模仍有限制
